
UT/インタビュー調査の音声を書き起こして活用する際、案件の性質上、クラウドの書き起こしサービスは使えないことが多いです。そのため、従来はAdobe Premiere Proのローカル書き起こし機能を使っていました(競合のDaVinci Resolve Studioも最近ローカル書き起こしに対応したものの、タイムコード出力ができないっぽいので、拙作の動画眼3でインデックスとして使うには対象外となっています)。
Premiere Proの音声書き起こしは無料で使えるものの、残念ながら固有名詞の追加学習が行えません。UTでは機能名や画面名など固有名詞が頻出し、それが言及された箇所を検索したい場合が多いので、「ローカルで使え、かつ固有名詞学習ができる」書き起こしツールを渇望していました。
そこで見かけたのが、ChatGPTで有名なOpenAIが公開しているWhisperという書き起こし(ASR)ツールです。Webサービスとして有料で利用もできますが、ツールとモデルは公開されており、ローカル環境にインストールしてオフラインで無料で利用することもできます。また自分でモデルをトレーニングしてボキャブラリーを増やすこともできるようです。
昨年導入したRTX4090を搭載したWindows PCにインストールしてテストしてみました。
詳細なインストール方法は割愛しますが、Python環境があればインストールコマンド数行で導入できると思います。
また学習済みのモデルも大小様々な規模で公開されています。今回は最新で最大のlarge-v3を使ってみました。使用したPCはCPUがAMD Ryzen9/5900X、メインメモリ64GB、GPUがNVidia RTX4090(VRAM 24GB)のWindows 11機です。
■精度
動画と書き起こしデータをリンクして参照できる拙作「動画眼Lite」形式にして下記にサンプルを置いてみます。書き起こされたまま一切の修正を加えていません。
タイムコードの部分をクリックすると当該箇所が再生されるので、書き起こされた文章と実際の音声を比べてみてください。
以下はWhipserによる書き起こしのサンプルです。
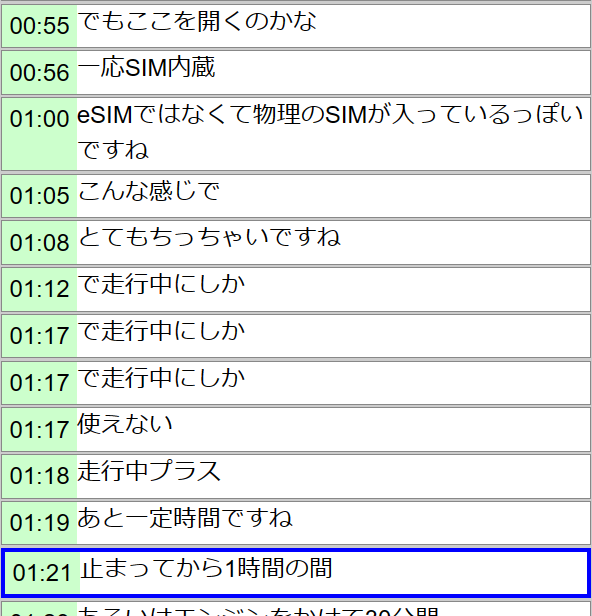
まず大きく違うのは、1つのブロックの長さです。Whisperはかなり細切れで、1息の発話も分割されてる感じ。これはもしかしたらパラメーター次第でどうにかなるかも知れません。
あと気になるのは1:12~1:17のところで「で走行中にしか」が3回繰り返されてる点。ここ以外でも割とあちこちに同じ現象が出ています。もちろん実際に何度もこういう発話をしているわけではなく、エコーのようなものが発生しています。最初、STTシステムにありがちな音声の途中の変換候補のようなものが更新の度に書き出されているのかなと思いましたが、必ずしもそうでもなさそう。–best_ofという候補数の増減オプションがあるんですがいじってみてもあまり効果がなさそうでした。そもそも実際の発話は1:16辺りなのに、1:12と数秒早い段階で出現してるのも不思議。
そんなこんなはありつつも、全体的な精度はかなり優れているという印象です。読んでて文章として成立しないような箇所が少ない。またeSIMのような最近のワードがしっかり書き起こしできるのは好印象。PremiereだとESIMになってました。
■処理速度、使用リソース
コマンドラインオプションは最低限で、パラメーターはほぼデフォルトの状態で、16分の音声ファイルを5分40秒ほどで処理できました。3倍速くらい。
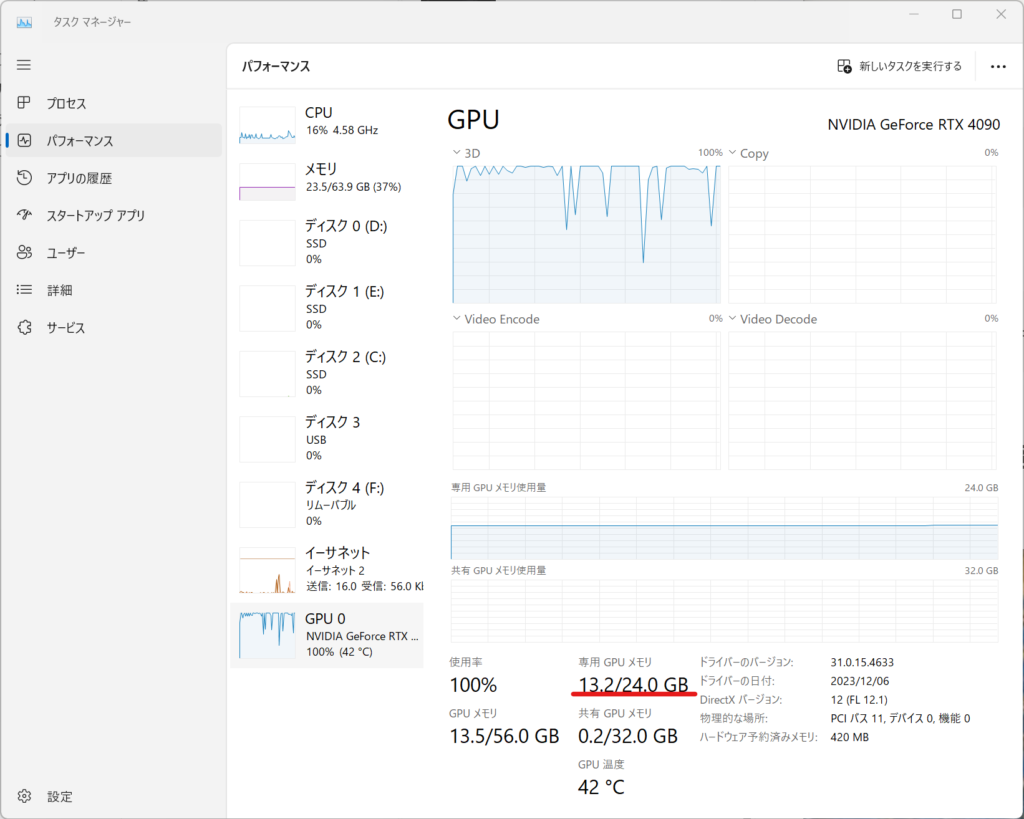
処理中のGPU使用率はこんな感じ。ほぼ100%張り付きで、VRAMは24GB中、コンスタントに13.2GBほど使用していたようです。16GB搭載の4080や4070Superでも実用になるかな?
■使用感
whisperに食わせられるのは音声ファイルなので、UTやインタビューの動画がソースファイルの場合、音声を分離してやる必要があります。今回はVLCを使って実施しました。ひと手間必要ですが、まぁVLCなら複数ファイルのバッチ処理もできるので、まぁいいかな。
mp4ファイルを直接食わせられました。
出力は字幕データによく使われるsrt形式で書き出しました。動画眼3はこの形式のインポートに対応しているので簡単に元動画ファイルとかけあわせて上記の動画眼Lite形式のデモが作成できます。
インストールが若干試行錯誤が必要でしたが、whisperコマンドが使えるところまできたら、あとはまぁ簡単かなという印象。パラメーターを詰めれば精度や速度が上がるかもですが、ちょろっといじった範囲ではデフォルトが一番正確に書き起こしてくれた気がします。
■単語学習(まだ難あり)
finetuningと呼ばれるモデルの再構築よりも手軽な方法として、優先使用したい語句をプロンプトとして与えてやるという方法があるようです。語句を半角スペースで区切って、
|
1 |
--initial_prompt "トヨタ 日産 ホンダ" |
のように与えてやります。ただし、この記事によると、initialとあるように、最初のブロック(ウインドウ)30秒にしか反映されず、2ブロック目は1ブロック目の認識結果でプロンプトが上書きされてしまう仕様のようです。
これを、最初から最後まで強制的にinitial_promptの内容を適用させるプルリクエストが提案されています。transcribe.pyというPythonスクリプトに対する改変なので、こちらの差分を見て、最新版のtranscribe.pyをテキストエディタで開いて適用させてみました(ピンクの行を削除し、黄緑の行を追加する)。ちなみに自分の環境では対象ファイルはC:\Python311\Lib\site-packages\whisper\にありました。再コンパイルも不要でwhisper.exeから–always_use_initial_prompt Trueオプションが使えるようになりました。
最終的に使用しているコマンドラインオプションは、
|
1 |
whisper.exe (音声ファイル名) --langage ja --model large-v3 --output_format srt --initial_prompt "hoge fuga moge" --always_use_initial_prompt True |
といった感じです。
ただ結果は微妙で、確かに誤認識していた箇所がプロンプトに加えた単語に置き換わってくれた箇所もあるんですが、逆に全然関係ないところでもその単語に引かれてみたり、しかも”トヨタ 日産 ホンダ”というプロンプトにしたら、「トヨタ 日産 ホンダ」というセグメントが大量に出現したりしました。もうちょっと研究が必要そうです。
やはり精度をあげるにはモデル自体を再トレーニングしないとダメかも知れません。
■まとめ
それなりの性能のPCが必要なものの、ローカルで実行でき、簡易的な単語追加も行えるOpenAIのWhisperを試してみました。
まだ色々パラメーターをいじったり、Pythonスクリプトで自動化やカスタマイズをする余地はありまsくりですが、とりあえずコマンドプロンプトでもPremiere Proよりもかなり「読める」書き起こしをしてくれるので、今後業務データを作る際にはこちらを使おうかなと思います。
2024.1.17追記:更に高速軽量で精度も高い関連ツールstable-tsを試しました。下記記事もあわせてご覧下さい。

スマホから