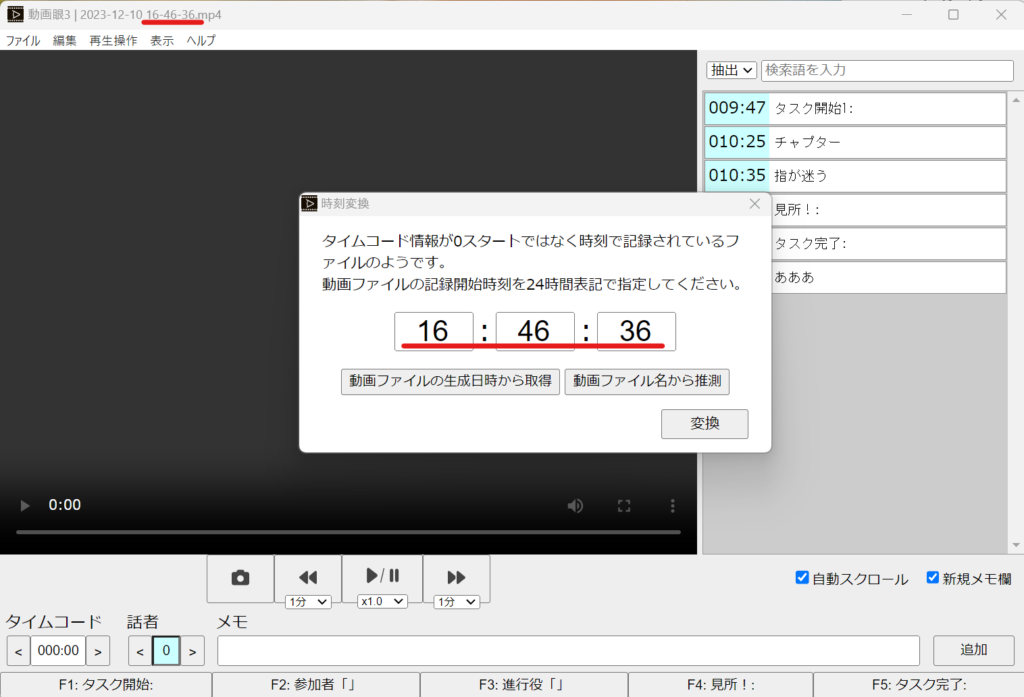
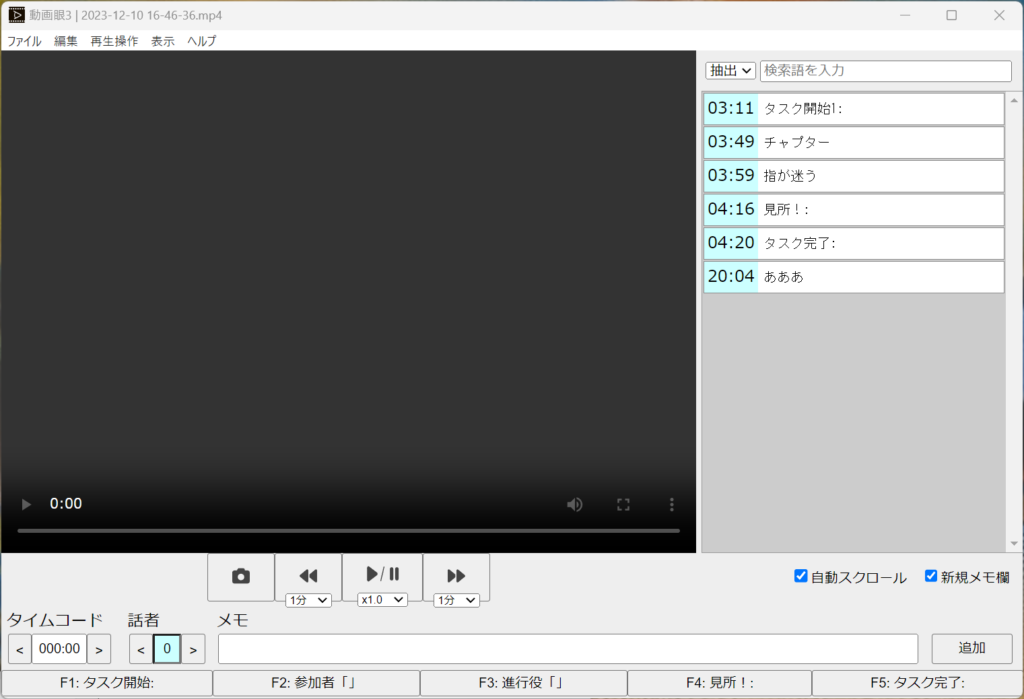
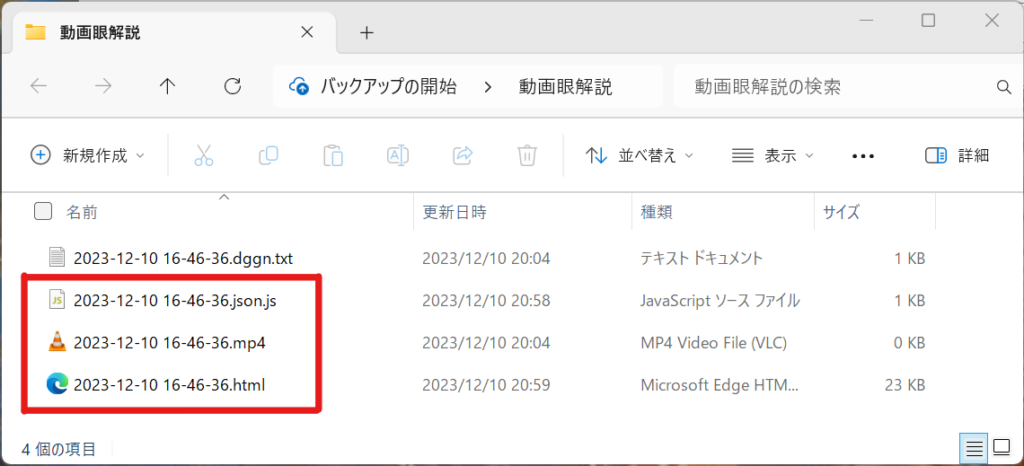
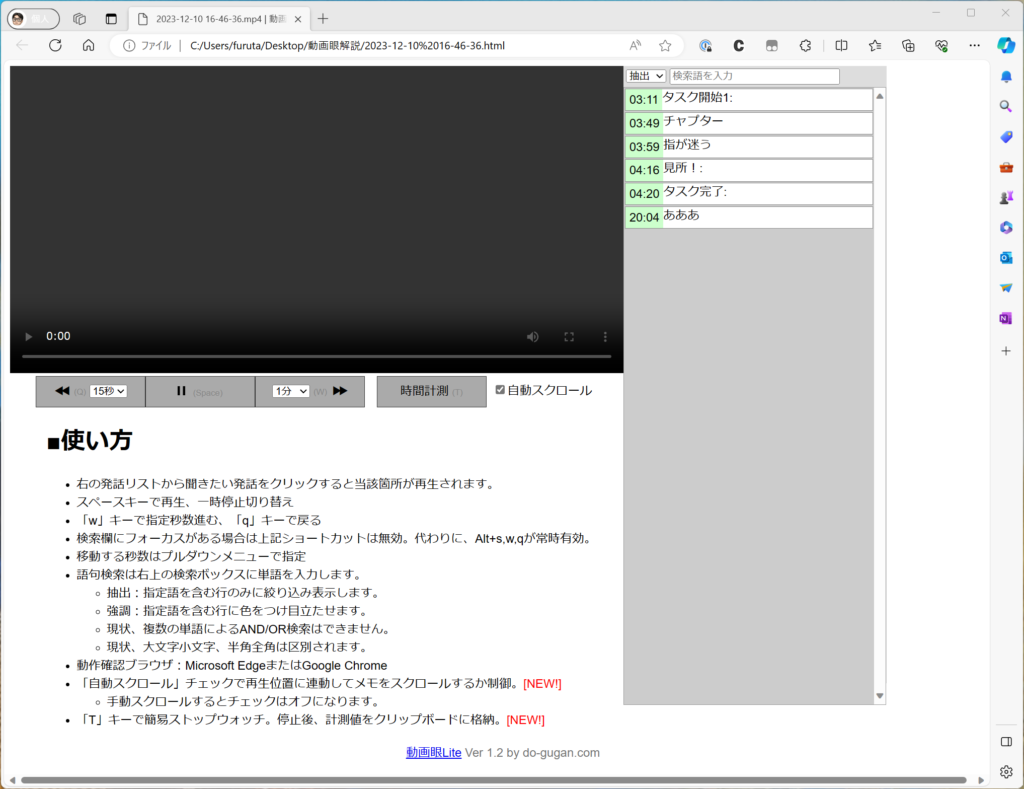
されこれらのマイクの共通の特徴として、マイク子機(トランスミッター)2台とPCやビデオカメラに有線でつなぐ親機(レシーバー)から成り立っています。レシーバーにはリアルタイムの音量(レベル)やバッテリー残量など重要な情報が表示されています。これをごちゃつきがちなモデレーターのデスクに見やすい位置に置いて、ステータス確認したい時にat a glance(チラ見)でチェックできるようにしておきたい、というのが本記事のトライアルです。
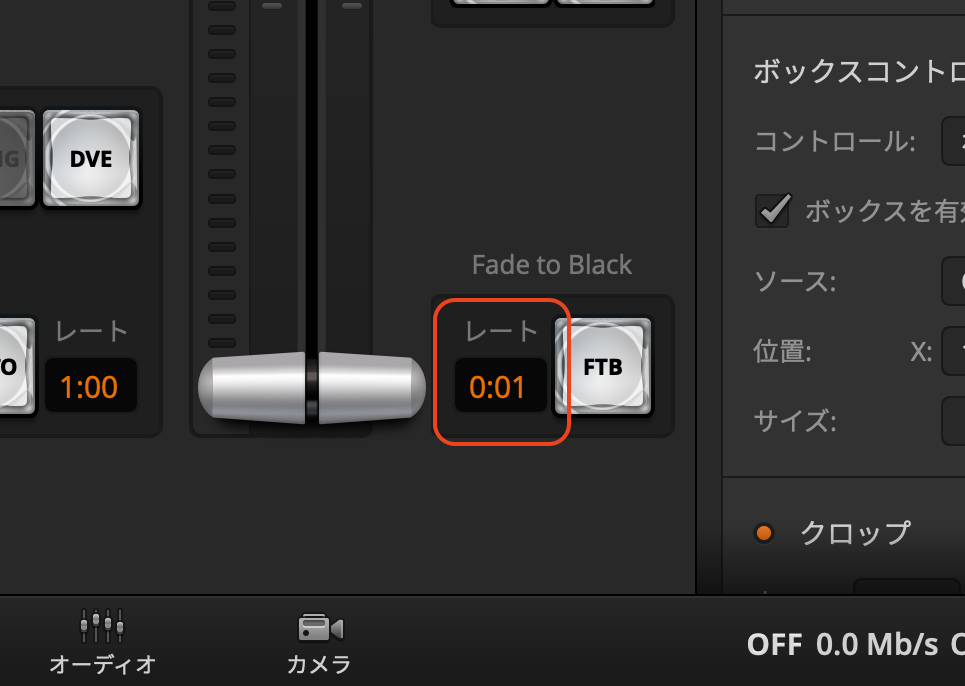
それは「動画の真っ黒なフレームを検出してチャプターにする」というアプローチです。例えばATEM MiniですとFTB(Fade To Black)ボタンがあります。1回押すとフェードアウトで画面が真っ暗になり、もう一度押すと解除されてフェードインで元の映像に戻ります。モデレーターなり録画オペレーターがタスクの切れ目などでこれを押しすぐ解除することで、録画/配信される映像が一瞬暗くなります。これを動画眼側で検知することでチャプターに自動変換できるのでは、と考え実証コードを書きました。どれくらいの黒を閾値とするかなどチューニングは必要ですが基本的に動いてる感じです。
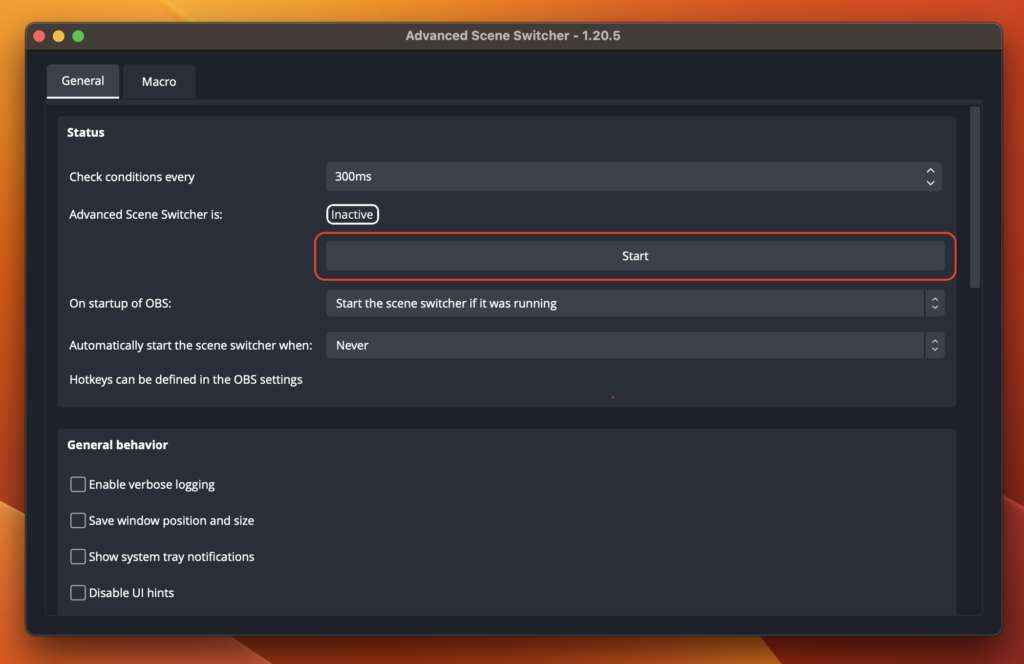
OBS Studio単体では実現できなそうなのでプラグインの力を借ります。Advanced Scene Switcherを使います。最新版はOBS Studio 28〜対応です。OBS Studioは27までと28以降でプラグインの規格が変更され互換性がありません。Advanced Scene Switcherの最新版を使う場合はOBSも28以降にしてください。どうしてもまだOSBを28以降にできない人はプラグイン側の旧バージョンを探してみてください。今回はOBS Studio 29.0.2にAdvanced Scene Switcher 1.20.5を使用しています。
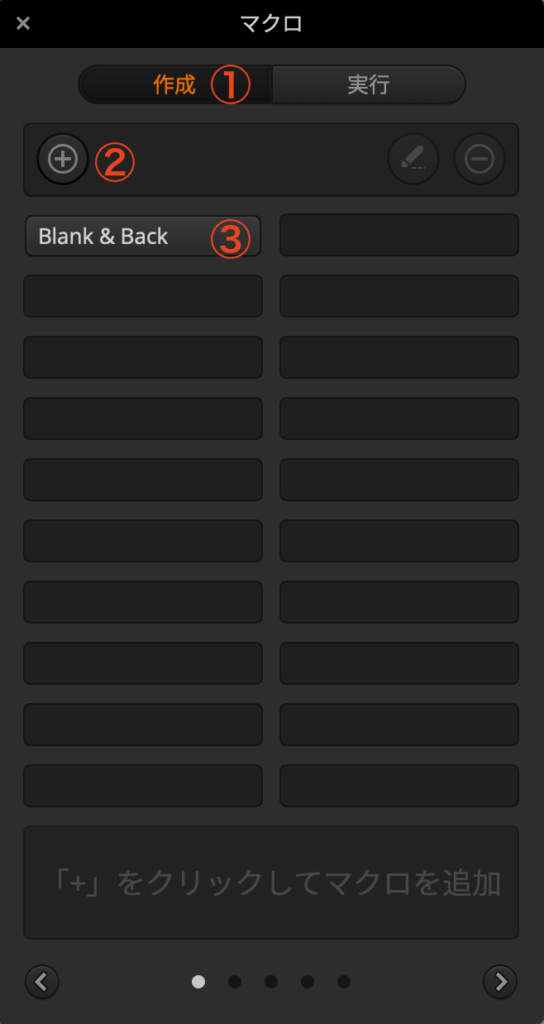
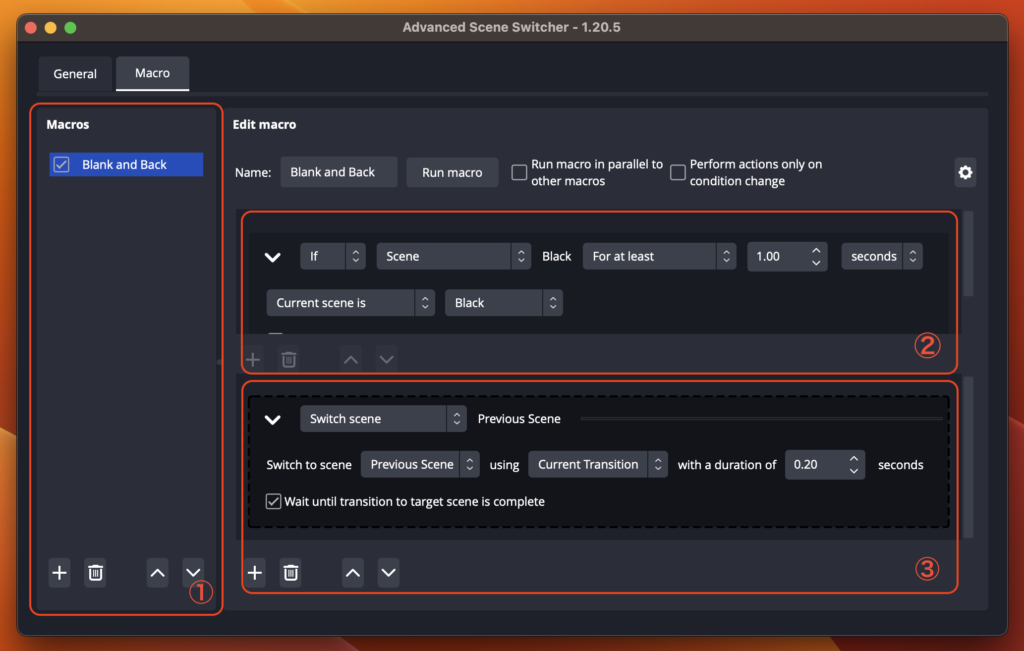
まず①のブロックで「+」から空の新規マクロを作成し、名前を決めます。ここでは「Blank and Back」としましたがなんでも良いです。
次に②のブロックでマクロ処理が発動する条件を定義します。ちょっと手順がややこしいですが、まず「If(もし)」「Scene(シーンが)」を選びます。すると下段に「Current scene is(現在のシーンが)」が選ばれて「–select scene–(シーンを選択)」が選択可能になるので、「–select scene–」を真っ黒シーンである「Black」にします。これで「シーンがBlackになった時」という発動条件が定義されました。更に冗談で時計マークが「No duration modifier(遅延指定なし)」にかわると思いますのでこれを「For at least(少なくとも)」に変更し「1.00」「seconds(秒)」にします。これで、「シーンがBlackになって最低1秒経過したら」という意味になります。