複数の映像ソースを画面合成して録画したり配信したりするビデオスイッチャーとかビデオミキサーと呼ばれるカテゴリの製品。自分はBlackmagic designのATEM MINIシリーズを初代からExtreme ISOと乗り換えて使ってきました。
入門機のATEM MINIでは二画面のPinP合成ができましたが、ユーザーテストで参加者の顔映像、手元映像、画面映像など3画面以上を合成したいこともあり、上位モデルのExtreme ISOに乗り換えたのが2022年。
【国内正規品】ブラックマジックデザイン ATEM Mini Extreme ISO SWATEMMINICEXTISO 黒
¥189,000 (2026/07/30 10:52時点 | Amazon調べ)
ポチップ
そろそろモデルチェンジか?でも4Kとかにすると一気に高性能プロセッサが必要になって値段上がりそう。ていうか買った時から円安進行で定価も上がってる。手の届く値段で後継機出るの?という感じでした。
また使っていていくつか不満も出てきていました。
HDMIx8系統はオーバースペック
基本現場に持ち込んで使うので大きい筐体は負担で、ノートPC+OBS Studioでいっかーとなりがち。自分の使用実績では最大で4入力なので、4入力モデルで3画面以上の合成ができるスーパーソースが使えるモデルが出ればなーと思っていました。
最近はHDMI出力のビデオカメラ/ミラーレスよりUSB Webカメラ
またカメラもミラーレスやビデオカメラよりも高画質なWebカメラの方がコンパクトにまとまるし参加者の目からも存在感を押さえられます。今まではOBSBotのUVC-HDMIコンバーターを使ったりして、電源配線などがゴチャゴチャしがちでした。
OBSBOT UVC to HDMI変換アダプター HDMI出力 UVC対応 4K解像度対応 ドライバー不要 シームレスに動く ゲー…
¥24,999 (2026/07/30 10:53時点 | Amazon調べ)
ポチップ
自由なレイアウトを組むスーパーソースの複数管理と切り替えがし辛い
基本3画面以上の入力を駆使する時に使うので、PinPではなくスーパーソースを使うのですが、それを複数パターン(シーン)組んで切り替えるのがあまり使い勝手がよくない。
基本1つしか作れないので、マクロを使って瞬時に再配置する感じになるんですが、そのマクロをアサインできるボタンが小さく押しづらいし、そもそもOBS Studioではなく専用機を使う場面は、自分が操作するのではなく誰かにまかせる時だったりするので、ボタンが見つけづらいのも難点。
3.5mmアナログでマイクをつなぐとノイズが乗ることがある(グラウンドループ現象)
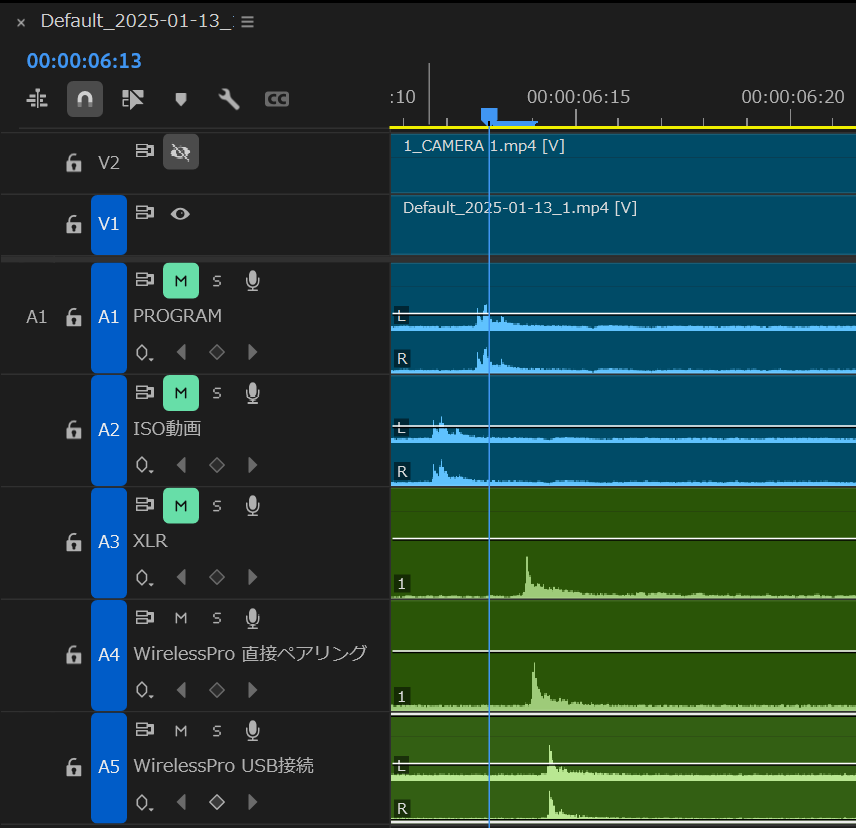
最近はRODE Wireless Proを使うことが多いですが、これをアナログ入力でつなぎ、かつ電源ラインをまとめたりすると、電気信号がループするとで起きるノイズが激しく乗ってしまし、ノイズアイソレーターを入れたり、電源を違うところから取ったりと工夫が必要になったり、これまた配線がゴチャつきがち。
たまーに熱暴走
動作するSSDが限られる
など。
そんな辺りが改善した後継モデルや競合機の登場を待っていました。YoloBoxとかOBSBot Talentとかタッチパネルモニター型の製品が出たりもしましたが、なんかAndridベースで大丈夫なん?とか高くね?とか思って躊躇してました。
■RODECaster Videoを導入!!
そんな2024年末に登場したのがあの音響機器メーカーRODEのRODECaster Videoです。
【国内正規品】RODE Microphones ロードマイクロフォンズ ロードキャスター ビデオ ブラック RCV
¥161,600 (2026/07/30 10:53時点 | Amazon調べ)
ポチップ
RODE Microphones ロードマイクロフォンズ ロードカバー ビデオ ロードキャスタービデオ専用保護カバー RCV…
¥5,178 (2026/07/30 10:53時点 | Amazon調べ)
ポチップ
個人的に上記不満点がいい感じに回避できそうでかなり刺さりました。値段は正直高いです。US価格が$1,199なのでほぼ為替通りとはいえ、ATEM MINI Extreme ISOが実売13万くらいなのを考えるとかなり強気ですね。果たしてそれに見合うメリットはあるのか?
先に挙げた不満点がどうなったか見て行きます。
[ATEMの不満1&2] HDMIx8系統はオーバースペック& 最近はHDMI出力のビデオカメラ/ミラーレスよりUSB Webカメラ→改善
本機はHDMIが4系統と必要充分な数に抑えられた上、、USB入力(カメラ&マイク兼用)が2系統という構成で、自分の使い方にはかなりフィット。UVC-HDMIアダプターも不要になります。
注意点としてはUVCのWebカメラならなんでもよいわけではなく、非圧縮映像を出せる機種でないとダメ な点。カメラ側でH264などにエンコードしてたらNG。非圧縮伝送だとデータ転送量が多いので、総じてUSB3.0を使ってるカメラが多い気がします。一応、公式の対応リストとしては以下が上がっています。
AnkerWork C310
Elgato 4K X
Elgato Cam Link 4K
Elgato Facecam
Elgato Facecam MK.II
Elgato Facecam Pro
Elgato HD60 X
Logitech Brio STream
Logitech Brio ULTRA HD Pro
Logitech C920 HD Pro
Logitech StreamCam
Obsbot Tiny 2
Razer Kyio Pro (おそらくKiyoの間違い)
Sony FX30
Sony FX3
Sony ZV-E1
我が家にはLogitech(Logicool)Brio、OBSBot Tiny 2、FX30があるのでまずまず困らなそう。なぜかクライアントが使ってることが多いC920も入ってるのもGood(あれ非圧縮だったんだ)。
ただしOBSBot Tiny2をつないだ場合、パンチルトズーム操作はできなくなります。入力解像度はフルHDまでなのでレイアウト時に拡大すると画質的にはちょっと不利かも知れません。
OBSBOT TINY 2 Lite Webカメラ 4K ウェブカメラ AI搭載 自動追跡 4800万画素 HDR 位相差検出AF フィルター…
¥23,840 (2026/07/30 10:53時点 | Amazon調べ)
ポチップ
OBSBot Tail Airはリストにないですがどうなんでしょ。こっちなら独立でリモコンから操作可能ですが、こちらはHDMIでもつなげられるんですよね。まぁ電源がUSB一本で済むのはいいかも。→NGでした
OBSBOT Tail Air ストリーミング PTZ リモート IP カメラ 4K UHD AI 搭載 人 動物 自動追跡 レーザーAF マ…
¥64,430 (2026/07/30 10:54時点 | Amazon調べ)
ポチップ
ポート類が最適化されて小型化はされたんでしょうか?RODECaster Videoの外形寸法、重量スペックは以下。
外形寸法 重量 ATEM Mini Extreme / ISO W370 x D136.6 x H39.6 1.235kg RODECaster Video W305.9 x D132.5 x H61.4 1.257kg
幅がかなり狭まったので小さく見えますが、高さが結構違っていて、縦x横x奥行きのかけ算で容積を出すとRODECaster Videoの方が2割程度大きいかな?ポート並びだけで言えばHDMIポートが水平に並んでいたATEMに比べ、縦配置になったので、その分高さも出たという感じでしょうか。どちらもトップが斜めなのでそう単純な比較もできないですが。重さは誤差レベル。重量と容積関係でいうと、RODECaster VideoはUSB PD 65Wで動くみたいなので、他の充電器と共有できれば多少荷物を減らせるかも?
[ATEMの不満3] 自由なレイアウトを組むスーパーソースの複数管理と切り替えがし辛い→改善
RODECaster VideoはHDMI x4 + UVC x2の6ソースボタンに加え、A~Gの切換ボタンがあり、それぞれにカスタムレイアウトをアサインできるぽいので、セッション中にインタビューパートとUTパートでレイアウトを切り替えるなんて時にわかりやすくかつ押しやすいと期待できます。
[ATEMの不満4] 3.5mmアナログでマイクをつなぐとノイズが乗ることがある(グラウンドループ現象)→仕様的には改善 ?検証待ち
RODEは音響メーカーだけあって、オーディオ周りがかなり強化されている印象です。
まずノイズに強いXLR入力が2系統あり、ファンタム電源が必要なコンデンサマイクも対応
UVCカメラと排他ではあるもののUSB端子にUACのマイクを2台接続可能
同じRODEのワイヤレスマイクを2台直接ペアリング可能
Bluetoothでスマホ通話音声もミックス可能
といった感じ。これらがオールインワンで最低限の外部配線で使えるのが魅力的すぎます。
ワイヤレスマイクはディレイの少なさでRODEしか勝たんと先日もWireless Proを買いましたくらいなので、RODE囲い込み上等です。親機の充電も気にしなくてよいなど、かなり機材構成をスッキリさせられます。
他、音声周りでいうと各種フィルタが使えるのはATEM MINIと良い勝負。映像との同期のためディレイをかけられますがおそらくオーディオミックス後でまとめてかけられるだけで、ソース毎の個別はできなそう。ワイヤレスマイクもRODE Wireless Proで統一したので、個別ディレイが必要になることはたぶんなさそうなのでまぁヨシ。
UTではあんまり使わなそうですが、音声入力にあわせて映像をスイッチすることも可能で、Web会議のように発話した人の顔が大きく映る、みたいな自動スイッチングもできるぽい。
また出力音声トラック毎にミックスがかえられるので、Bluetooth経由で通話参加している人に自分の声を返さないミックスマイナス、マイナスワン的なセッテイングもできるはず。
[ATEMの不満5] たまーに熱暴&動作するSSDが限られる→検証待ち
この辺りのカタログスペックに出てこないロバストネスは実際に使ってみないとなんともですが、観測範囲ではATEMほど熱暴走するとか冷却必須とかいう話は聞こえてきてないです(というか日本のレビューはまだほとんどない)
その他の進化点
これまで有線LANのみだったATEMに対し、本機はWi-Fiにも標準で対応しました。直接配信に使えるのももちろんですが、管理ツールによる設定作業も無線でできるのが良き。個人的にRTMPで直接ライブ配信サービスに使うことはなくて、PC経由でZoomなどクローズドなWeb会議に流すのがメインなので、主に後者です。例えば配信用PCへは有線でつなぐけど、スイッチング操作やオーディオ調整などは別室のPCから補助スタッフが行うなんて時に、LAN接続が不要になるならハブからのケーブル取り回しを考えなくてよくなります。
管理ツールの複数人同時使用でいうと、USBポートも配信用(UVC出力)のUSB1と別に操作PC専用のUSB2がついたので、USB接続の場合も配信と操作を別々のPCから行えるようになりました。
ということで年末駆け込み経費で注文しちゃった(てへぺろ
発表直後に少し迷っていたら、日本代理店の銀一 で早々に初回入荷分は売り切れで、次は2ヶ月前後ほどかかる見込みとの表示。ヨドバシ、ビック、Amazonなども在庫無し、入荷未定な雰囲気で、来年使いそうな案件来た時に探すかーとなってました。
しかし年の瀬ギリギリになって、節税的になんか買っておこうかってなった時に、最近のMacBook Proは30万軽く超えて一括償却できないし、コイツが手頃かも!と思って探したら奇跡的にシステム5さんに在庫1表示が!大晦日だったので発送は休暇明けになりますが、速攻で注文を入れました。
■届いた!使用感チェック
年明け営業開始初日に発送され、本日届きました。とにかくどこも品切れの商品なので「やっぱ在庫切れてましたがスンマソン!」って言われる可能性も考えていましたが、無事届いてひと安心です。
ATEM MINI Extreme ISOとサイズ感比較
さっそくATEM MINI Extreme ISOと並べてみました。
やはりATEM MINI Extreme ISOよりは短いが高いという感じですね。これはまだ2本のWi-Fiアンテナを装着していない状態です。横からみた状態は倒したL字のようですが、実際は底面はフラットになっていて、直角三角形といった方が正しいです。底の部分にはファンを含めた冷却機構が収まってるようです。
持ち運びはどっちが楽かというと悩ましいところです。またATEM MINI Extremeは社外製のアクリルカバーがあったんですが、本製品にはまだそういったサードパーティアクセサリが充実しておらず、突起物であるダイアルやWi-Fiアンテナを保護しつつ持ち運ぶか、ケース探しからやり直しです。
現時点でポータビリティは互角というところでしょうか。
傾斜している分、デスクで使う時には扱いやすいと思います。そしてなんといってもボタン数が少なく、個々のボタンが大きく押しやすいのは長所です。先にも書きましたが、自分はモデレーターの集中して、誰かスイッチ操作をお願いします、ってなった時に「ここ押してくれればいいから」がとても言いやすいです。
電源周り
ATEM MINI Extremには電源スイッチがなく、専用ACアダプタのネジ式のロックコネクターを抜き差しすることでオン/オフします。正直煩わしさもありました。専用ACアダプタ忘れたらアウトだし、数日の実査で毎日電源を落として帰る度にネジをクルクル回してコネクタを抜くとかが地味に面倒。ケーブルがテーブルの裏に落ちてしまったりとか。
対して本機はUSB Type-CコネクタのPD(Power-Delivery)65Wの電源仕様です。汎用品が使えるので、もしもの時も調達しやすいです。ケーブルを抜き差ししなくても電源ボタンでオン/オフできるのもGood。ただそれ故に恐い部分もあって、
ロック機構がなく簡単に抜ける
マルチポートUSB充電器は鬼門
複数のType-C(PD)給電ができるマルチポート充電器は、どこかのポートに挿抜が発生すると、一度全てのポートの電源を落としてから改めて各ポートへの配分を決定して再給電する仕様のものが少なくありません(というかほとんどそうです)。つまり、同じ充電器でマイクを充電しておき、「さぁ始まるぞ」とマイクを抜いたら本機が落ちます(恐。実査中(配信中)に予備マイクと入れ替えようと思って抜き差ししても落ちます。これは別に本機が悪いわけではないのですが、運用としては注意が必要そうです。OBS Studioで外付けのモバイルモニターの画面をキャプチャして配信している時によくやりました。モニターが切れてOSが画面を見失うとOBS Studioはクラッシュするので、配信事故ります。モバイルモニターにしろ本機にしろ、マルチポート充電器で他機器と共有せず、付属アダプタなど1ポートのみで専用ラインを用意した方が良いでしょう。
この辺り、テレビ放送機器メーカーのBlackmagic Design(ATEMのメーカー)と、(個人的イメージですが)ハイアマ/プロシューマー位までがメインのRODEで考え方の違いを感じて興味深いです(優劣ではなくRODEはRODEで利便性ではメリットが大きいと思います)。
ソフトウェアも含め操作が圧倒的に楽で直観的
上述のハードウェアボタンの少なさもそうですし、管理ソフトのRODE Centralから行うシーン設定も圧倒的に楽です。例えば画面内に複数の映像ソースを並べてレイアウトを組む際、ATEMのはx位置/y位置/サイズ(ズーム率)を数値で入れていくUIでした。アスペクト比を変えたり一部を切り抜くなら別項目の「クロップ」で上/下/左/右をまた数値指定。これがなんともめんどくさい。APIが公開されているのでサードパーティソフトを使えば幾分マシではありましたが。
それと比べRODE CentralのScene BuilderならOBS StudioやPowerPoint感覚で各ソースの枠を直接ドラッグ&ドロップして位置、縮尺、クロップを直観的に制御できます。ATEMはなぜこれを実現してないのか小一時間問いたい、問い詰めたい。
しかも複数シーンを7つのハードボタンにアサインしてサクサク切り替えられます。ATEMは各パラメーターを変更するマクロを組んで、小さな6ボタンに割り振る感じ。ハードボタン総数がエゲつないので、人にも教えづらいです。
各ソース毎の音量調整も、ATEMは▲/▼ボタンでポチポチで、しかも現在のレベルはハード上では視覚確認できませんが、本機は内蔵液晶でレベルメーターを見ながらダイヤルで調整できます。ソース毎に画面切り替えは必要ですが、ダイヤルでの回転と押し込みで上手く調整できるようになっているという印象です。
そんなこんなで、必ずしも専門要員がいない手弁当状態のプロダクトリサーチ系の現場にはかなり薦めやすいユーザビリティを備えていると言えます。
配線周りがシンプルに
先にも触れたことも含みますが、
USB(UVC)入力が2ポートついて、UVC-HDMIコンバーターを使わなくてもWebカメラを映像ソースとして使えるようになった
RODEのワイヤレスマイクを親機接続不要で直接ペアリングして音声ソースとして使えるようになった
録画用ストレージとしてUSB接続のSSDだけでなく内蔵microSDカードスロットも使えるようになった SSDは合成素材読み込み用で、録画はUSB SSDが必要っぽい
といった点が重なって、使用時の接続ケーブル数や電源系統数が劇的に減る結果となりました。出張業務での持込荷物点数が減るとか信頼性の面でもメリットは大きいです。
■まとめ
2022年に導入したATEM MINI Extreme ISOから今回新登場の競合機器のRODE RODECaster Videoに乗り換えました。できることは大きくかわらないですが、設営や操作をシンプルにできより安定した収録ができそうで実践投入が待ち遠しいです。
とりあえず自宅で耐久録画/配信テストをしてみてまた追加で気付いた点などあれば追記するか別記事を出したいと思います。
また手持ちUSBカメラで試しまくってみた動作検証記事書きましたので、ご興味あればご覧ください。UVC/UAC機器を入手したら随時更新していこうと思います。
PDA工房さんにオリジナル液晶保護フィルムを製作してもらったので、プライベートブログの方で記事にしました。
純正カバーの様子はこちら。